
Je hodně věcí, o kterých se dá mluvit v souvislosti s jazykem C. Nechci sem psát učebnici, protože je jich napsaných spousta. Mám ale dojem, že je potřeba napsat malý přehled toho, co byste měli v souvislosti s programováním mikroprocesorů vzít jistě v potaz. Zde tedy nabízím výcuc, který by každý náš student měl během 3. ročníku zvládnout.
Nebo možná jinak: Vše, co je zde zmíněno (i to, na co se jen odkazuji) byste fakt měli znát! Bez toho se nehnete. Buď je to zde přímo vysvětleno, nebo je zde odkaz na zdroj ze kterého byste to měli pochopit, ale v každém případě byste se tím měli vážně zabývat.
- Učebnice:
- Klasika je učebnice jazyka C je ta od Pavla Herouta. Patří k ní i druhý díl, ale ten není pro embeded programování tolik důležitý.
- Další je C pro mikrokontrolery
- … a Programovací jazyk C pro zelenáče

Pokud hledáte nějaký online návod nebo referenční příručku, můžete začít třeba tu:
- https://www.sallyx.org/sally/c/
- https://www.w3schools.com/c/
- https://www.tutorialspoint.com/cprogramming/index.htm
Funkce main a ostatní funkce¶
Hlavní program se nachází v funkci main. Funkce main tedy musí být v každém
programu/projektu. V našem případě by funkce main měla obsahovat nekonečnou
smyčku hlavního programu. Procesor musí stále něco dělat, proto musí běžet v
nekonečné smyčce. Nekonečnou smyčku vytvoříme pomocí cyklu while nebo for.
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 8 9 | |
Obecně vypadá hlavička funkce takto:
datový_typ_návratové_hodnoty název_funkce(datový_typ_parametru jméno_parametru)
konkrétně pak takto:
1 2 3 4 5 6 7 | |
Funkce jménem prevod vrací 16-bitové číslo datového typu int16_t. Jako
parametry funkce přebírá dvě 8-bitová čísla a a b typu int8_t.
Funkci potom můžeme volat třeba takto:
1 2 | |
Pokud funkce nic nevrací, nebo nemá žádné parametry použijeme klíčové slovo
void.
1 2 3 4 5 6 7 | |
Když funkci voláme, musíme vždy uvést závorky, i když nepřebírá žádné parametry:
1 | |
Jak je to vlastně s kompilací?¶
Mějme tento zdrojový text:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
U jazyka C se převod zdrojového textu do strojové hexadecimální podoby děje v několika fázích.
Nejprve se zdrojový text předzpracuje pomocí preprocesoru — ten vloží do
zdrojového textu hlavičkové soubory a expanduje všechna makra.
Všechny direktivy, kterým rozumí preprocesor začínají znakem #.
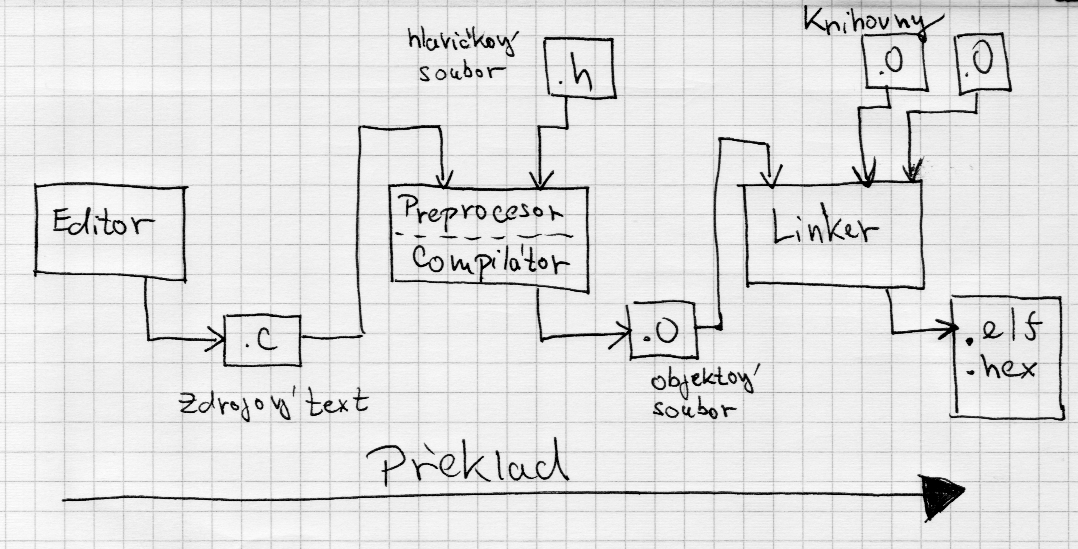
Následuje zpravování kompilátorem. Ten převede zdrojový text do podoby
relativního objektového kódu příslušného mikroprocesoru. To je již téměř
hotový program ve strojovém kódu, ale adresy použitých proměnný a funkcí
ještě nejsou známé a jsou tedy jen relativní. Výsledkem je objektový soubor s příponou .o nebo .obj.
V našem příkladu je volána funkce GPIO_Init, jejíž tělo (definice) je ale
uvedena v jiném souboru, který se překládá samostatně. Kompilátor tedy v
tuto chvíli nezná konkrétní adresu, na které se funkce nachází — proto/protože
neví na jaké konkrétní adrese v paměti mikropočítače bude funkce uložena.
V poslední fázi se relativní adresy proměnných a funkcí nahradí skutečnými
adresami na kterých budou tyto proměnné a funkce uloženy v paměti
mikropočítače. Tato fáze se označuje jako linkování (linking time) a
provádí je linker. Jsou k tomu potřeba všechny objektové soubory celého
projektu: tedy zdrojový text s funkcí main a všechny knihovny, které také
museli projít procesem kompilace. Teď už bude možné zavolat funkci GPIO_Init,
protože linker do strojového kódu vloží její skutečnou adresu.
Více je toto téma rozvedeno v postu Oddělená kompilace a vlastní knihovny.
Základní datový typy¶
Při embeded programování potřebuje v naprosté většině případů pracovat s celými
čísly nebo s reálnými čísly pomocí pevné řádové
čárky. Je tedy třeba si
vystačit s celočíselnými datovými typy. C sice nabízí datový typ float, ten
pro nás ale z důvodů omezené paměti není většinou vhodný.
Klasické C nabízí
datové typy
char, short int, int, long int, long long int.
Specifikace ale neuvádí konkrétní počet bitů, který se pro daný datový typ má
použít — toto závisí na konkrétním kompilátoru a každý kompilátor to má jinak.
Jediná zaručená věc je toto:
1 | |
Operátor sizeof
vrací počet bytů, použitých v paměti pro danou proměnnou.
Například kompilátor SDCC to má takto:
| type | počet bit | počet byte |
|---|---|---|
| char | 8 bits | 1 byte |
| short | 16 bits | 2 bytes |
| int | 16 bits | 2 bytes |
| long | 32 bit | 4 bytes |
| long long | 64 bit | 8 bytes |
Protože každý kompilátor je trošku jiný nikdy si nemůžete být jistí, kolik
paměti kompilátor proměnné přiřadil používají se v embeded programování
datové typy které to zaručují a kde je vše jasné hned na první pohled.
My je máme definovány v knihovně SPL a jsou dostupné jakmile zavoláme
#include stm8s.h.
Je pravidlem, že vlastní/uživatelské datové typy užívají postfix _t. Písmeno u na začátku znamená unsigned — tedy bez znaménka. Do takové
proměnné můžeme tedy ukládat pouze kladná čísla.
| type | znaménko | počet bit | číselný rozsah |
|---|---|---|---|
| int8_t | kladná i záporná | 8 | -128 až 127 |
| uint8_t | nezáporná | 8 | 0 až 255 |
| int16_t | kladná i záporná | 16 | -32.768 až 32.767 |
| uint16_t | nezáporná | 16 | 0 až 65535 |
| int32_t | kladná i záporná | 32 | -2.147.483.648 až 2.147.483.647 |
| uint32_t | nezáporná | 32 | 0 až 4.294.967.295 |
Je myslím také dobré zmínit, že int8_t je ekvivalent k char a uint8_t je
ekvivalent k unsigned char. Rozdíl je ale v čitelnosti programu. Pokud
proměnnou deklaruji jako char bude její hodnota zřejmě představovat nějaký
znak, jehož číselná hodnota je v ní uložena.
Řízení běhu programu¶
- Podmínky a cykly
- Pro
větvení se
používá výraz:
if,if .. else,switch. - Cykly máme k
dispozici ve třech podobách:
while,do while,for.
Čísla a operace¶
Čísla a
konstanty je
možné zapisovat v desítkové, osmičkové (prefix 0), šestnáctkové (prefix 0x)
nebo dvojkové (prefix 0b)soustavě. Přičemž písmenko na konci čísla (U, L)
udává datový typ.
1 2 3 4 5 6 7 8 9 | |
Znaková konstanta je číselná hodnota zadaná pomocí znaku. Konkrétní číselná hodnota konkrétního znaku je dána Ascii tabulkou. Zapisuje se do apostrofů.
Oba tyto zápisy jsou ekvivalentní:
1 2 3 4 | |
Operátory zde nebudu zevrubně popisovat ale jen zdůrazním následující:
Zaokrouhlování: Operátor / je dělení a jeho výsledek závisí na tom, s jakým datovým typem je
proveden. My používáme většinou celá čísla. Je to tedy celočíselné dělení.
Nedochází zde k zaokrouhlování, ale useknutí desetinné části, takže výraz
40 / 21 bude 1.
Operátor % je zbytek po celočíselném dělení takže 40 % 21 je 19.
Dále je třeba si dát pozor a neplést si bitové a logické operátory.
Logické operátory && AND, || OR a ! NOT pracují s pravdivostní hodnotou.
Například:
1 2 3 | |
Bitové operátory & AND, | OR, ^ EXOR a ~ NOT, <<, >> provádí bitové
s čísly.
Například:
1 2 3 4 | |
nebo
1 2 3 | |
Pravda a nepravda¶
Pravdivostní hodnota je reprezentována čísly 0 a 1. To ale není vše.
Každé číslo může být použito jako pravdivostní hodnota. Jako Nepravda —
false se interpretuje pouze číslo 0. Všechna další čísla od nuly různá se
interpretují jako Pravda — true. Tohoto se často využívá. Typické je to
například, když překládáme masku přes číslo, abychom zjistili stav
jednotlivých bitů.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Maska zde nabývá hodnot
0b10000000,
0b01000000,
0b00100000,
0b00010000,
0b00001000,
0b00000100,
0b00000010 a
0b00000001. Ve chvíli kdy nabude hodnotu 0b00000000 z cyklu se vyskočí.
Podobných hodnot nabývá výraz cislo & maska v podmínce if.
Návratová hodnota¶
V Céčku má každý výraz vždy sou návratovou hodnotu a tuto návratovou hodnotu lze uložit do proměnné.
Například i++ nebo ++i přičítá k proměnné jedna. Rozdíl je ale právě v
návratové hodnotě. Pokud použijete i++, nejprve se je vrácena hodnota i a
potom teprve se přičte jedna. Pokud použijete ++i, nejprve se přičte jedna a
potom teprve se vrátí hodnota již inkrementovaného i. Analogicky platí totéž pro
i-- a --i;
1 2 3 4 5 | |
Podobně lze návratovou hodnotu použít jako pravdivostní výraz v podmínkách a cyklech. Například takto:
1 2 3 4 | |
Ukazatele, pole, řetězce¶
Ukazatel — pointer¶
Ukazatel je proměnná, která neobsahuje data, ale adresu na které se nachází
data. Prostě a jednoduše ukazatel je proměnná obsahující adresu proměnné.
Proměnná typu ‘ukazatel na int‘ obsahuje adresu, na které se v paměti nachází
číslo typu int. Ukazatel se deklaruje a vyhodnocuje pomocí operátoru *.
Adresa paměti se získá pomocí operátoru &.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Ukazatelů se dá použít, když mám například 32-bitovou proměnnou a potřebuji z ní dostat odděleně čtyři 8-bitové (1B) proměnné. Mohlo by to vypadat například takto.
Pole — array¶
Pole představuje kolekci několika hodnot stejného datového typu umístěného v paměti vedle sebe jednu položku po druhé. Ke každé položce této kolekce lze přistupovat zvlášť pomocí indexu.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Pole a ukazatel jsou v Céčku velmi úzce svázané. Proměnná cislo je typově
kompatibilní s ukazatelem na int int *. V proměnné cislo je uložena adresa,
na které začíná kolekce deseti po sobě jdoucích hodnot.
Ještě je potřeba říct, že Céčko nijak nehlídá jestli náhodou index nepřesáhl
stanovenou mez. Takže výraz cislo[22] = 51; se normálně provede, ale přepíše
se část pamětí ve které se v danou chvíli nachází třeba jiná proměnná. To může
vést k naprosto neočekávanému pseudonáhodnému chování.
Řetězec — string¶
Řetězec je “jen” pole znaků. Dá se s ním tedy pracovat stejně jako s polem.
1 2 3 4 5 6 | |
Každý správný řetězec v Céčku končí znakem \0 s ascii hodnou 0 (nula). Podle
tohoto se dá spolehlivě rozpoznat, že řetězec už na konci — přestože paměť je
alokovaná pro více znaků než řetězec obsahuje.
Makra¶
Makra preprocesoru představují velmi mocný nástroj jak si zpřehlednit zdrojový kód. Při programování mikrokontrolérů představuje definice správných maker více-méně nutnost, bez které se v kódu velmi rychle ztratíte. Poměrně dobře jsou možnosti preprocesoru popsány na www.sallyx.org.
V nejjednodušším případě je makro nějaká zkratka nebo konstanta. Všude, kde se ve zdrojovém kódu vyskytne toto makro, je nahrazeno jeho obsahem. Případná změna tedy proběhne jen jednom místě — při definici. Makra se provádí (expandují) ještě před zahájením kompilace. To je velký a zásadní rozdíl oproti proměnným, které se nachází v paměti.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
V našem případě budeme marka používat pro pojmenování jednotlivých pinů. To je velmi užitečné, protože budeme moci s minimálním zásahem do kódu přemístit jednotlivé periferie nebo portovat projekt na jiný mikrokontroler.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Já osobně si ještě dělám vždy sadu maker s parametrem, která mi umožňuje
efektivně číst a zapisovat stav jednotlivých pinů (operátor ## provádí zřetězení):
1 2 3 4 5 6 | |
Místo poměrně těžkopádného:
1 | |
… můžu napsat
1 | |
Kód se tak lépe zapisuje, čte i portuje na jinou platformu.
Další datové typy¶
typedef enum a switch -– case¶
V embedded programování se velmi často pracuje se stavy, režimy nebo výčty
chybových kódů. Místo holých čísel (0, 1, 2…) je výrazně čitelnější použít
enum – pojmenovaný výčtový typ. Kódu pak místo tajemného
1 | |
píšeme dobře čitené
1 | |
a je okamžitě jasné, co se testuje. Velmi často se v tomto případě místo if-else
používá switch–case, protože jeho zápis je o chlup přehlednějíší a pohodlnější.
enum¶
Takto vypadá definice nového výčtového (enum) datového typu:
1 2 3 4 5 | |
Proměnná typu LedState může nabívat hodnot LED_OFF, LED_ON a LED_BLINK.
Kompilátor přiřadí prvnímu prvku hodnotu 0, dalším 1, 2 … Hodnoty lze ale
přepsat explicitním přiřazením – hodí se například pro chybové kódy nebo
komunikační protokoly, kde čísla musí odpovídat přesné specifikaci:
1 2 3 4 5 6 | |
Pokud se explicitní hodnota uvede jen u prvního prvku, ostatní pokračují od něj: { STATE_IDLE = 1, STATE_RUN, STATE_DONE } dá hodnoty 1, 2, 3.
Proměnnou výčtového typu deklarujeme a inicializujeme úplně stejně jako každou jinou celočíselnou proměnnou:
1 2 3 4 5 | |
switch — case¶
Příkaz switch vezme hodnotu proměnné (nebo libovolného celočíselného
výrazu) a podle ní skočí na odpovídající větev case. Jde tedy o
vícecestné větvení – náhradu za sérii if–else if–else if…, která
by pro větší počet možností byla těžkopádná. Kód se switch–case čte
přirozeně: „přepni se podle hodnoty stav: je-li LED_OFF, udělej
tohle; je-li LED_ON, udělej tamto; …”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Klíčové slovo case funguje jako návěstí (label) – označuje místo, kde
program do bloku switch vstoupí, pokud se hodnota výrazu shoduje. Odtud
pak program pokračuje řádek po řádku dál, jako by tam žádné case nebylo.
Proto je nutné každou větev ukončit příkazem break – ten celý blok switch
opustí a skočí na kód za uzavírací složenou závorkou. Bez break by program
„propadl” do následující větve (fall-through) a provedl by ji také, bez
ohledu na podmínku. Toto chování je záměrné jen výjimečně (např. když dvě
hodnoty mají sdílet stejný kód); jinak jde o klasickou chybu.
Větev default není povinná, ale je důležitá: pokryje situaci, kdy se do
proměnné dostane neočekávaná hodnota (např. neinicializovaná paměť nebo
budoucí rozšíření výčtu).
Poznámka 1: switch pracuje pouze s celočíselnými typy (int, char,
enum apod.). Pod kapotou je enum jen int, takže vše funguje přirozeně. S float ani řetězci switch nelze použít.
Poznámka 2: Prvky výčtu jako LED_ON nebo ERR_TIMEOUT jsou pojmenované
celočíselné konstanty – píšeme je přímo, bez uvozovek. Uvozovky patří jen
řetězcům ("text"), apostrofy znakům ('a'); tady nejde ani o jedno.
Poznámka 3: switch-case není nijak pevně spojen se datovým typem enum a lze
ho použít vždy, když potřebujeme větvit program podle celočíselné hodnoty —
ať už jde o obyčejná čísla nebo znaky:
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 8 9 | |
Jak více-Bytovou proměnnou rozřezat na jednotlivé Byte.¶
Pří práci s µkontrolerem a různými periferiemi lze poměrně často narazit na úlohy typu: Mám data v 32-bitové (4-Bytové) proměnné, ale abych je mohl zobrazit potřebuji každý Byte zvláště. Potřebuji tedy 32-bitovou proměnnou rozdělit na čtyři 8-bitové proměnné. Dá se to udělat celkem asi třemi různými způsoby. Mě osobně přijde nejhezčí a nejpřehlednější ten druhý.
1. Masky¶
1 2 3 4 5 6 7 8 9 | |
2. Uniony¶
1 2 3 4 5 6 7 8 9 10 11 12 | |
3. Ukazatele¶
1 2 3 4 5 6 7 8 9 | |
Moduly a externí proměnné¶
Toto téma naleznete v samostatném postu Oddělená kompilace a vlastní knihovny.
